基本統計量
基本統計量とは
データの基本的な特性を表すものです。分布全体を一つの数で表す代表値とデータのばらつきの大きさを表す散布度に大きく分けられます。
データの落とし穴

商品企画の担当者が、新しい商品の品揃えを検討するためにIT担当者に顧客の平均年齢を問い合わせました。平均年齢は32歳との回答を得て、30歳前後をターゲットとした品揃えを実施したところ売上が減少を始めました。しかしなぜ売上は減少したのでしょう。担当者が顧客の年齢データを確認すると、19歳×3名、20歳×6名、21歳×3名、100歳×1名、102歳×1名でした。確かに平均年齢は32歳ですが、ターゲットとしていた30歳前後は存在していません。
見落とされがちなデータの特性
データを表すものとして平均が一般的ですが、それだけを見てしまうと上記のような落とし穴にはまることがあります。もし、過去6ヶ月の売上を平均としてみた場合、特定の月だけが突き抜けて多かったときに同じような問題が発生します。このような問題を避けるためには、実際のデータを確認し、または散布度といわれるばらつきを確認することで回避することができます。
利用事例
たとえば、こんなときに
先月の売上がどの程度か知りたい
現在の顧客の年齢層はどのくらいか知りたい
スタッフにより特定商品の販売数にばらつきはあるか
こんなことができます
売上データから平均値を算出します
顧客の年齢データから最頻値を集計します
販売数から標準偏差と分散を算出します
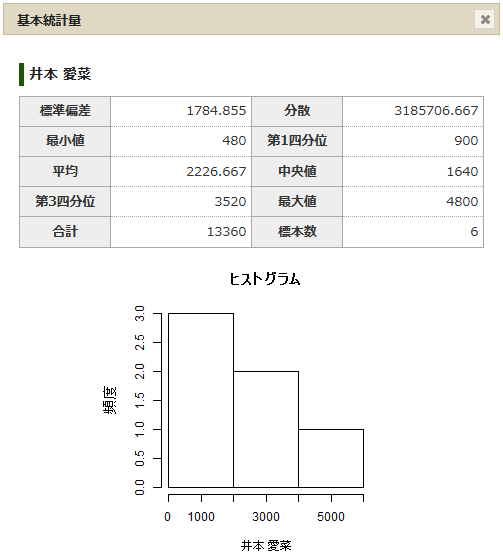
基本統計量の概要
基本統計量は、いくつかの数値で表されます。
標準偏差
データが中心値の近くにばらついている時はばらつきが少ないといい、データの中心値から遠くはなれたところまでばらついている時はばらつきが大きいといいます。ここでの散布度(ばらつき度)は、一般にデータの平均的なばらつき度を問題としています。このばらつき度の尺度として最も用いられるのが標準偏差です。標準偏差とは“各データの中心からの距離の平均”であり、“中心からの平均的距離”、“平均的偏差値”ということができます。分散では“中心値からの平均的距離の2乗”であり、これを“中心値からの平均的距離”に直すために、分散のルート(平方根)を算出します。これが標準偏差となります。
エクセルでは、STDEV(データの範囲)で算出されます。
分散
統計で大切なことの1つに「分散」の理解があります。分散の意味が分かることにより相関や回帰分析の理屈も理解できるようになります。分散は、[(各データの値-平均)2の合計/データ個数]で算出されます。この値が大きいほうが、平均から各データがばらけていることが分かります。
エクセルでは、VAR(データの範囲)で算出されます。
最小値
データの中の一番小さな値です。
エクセルでは、MIN(データの範囲)で算出されます。
第1四分位
一番小さな値から25%目の値です。 エクセルでは、QUARTILE(データの範囲, 1)で算出されます。
平均
いわゆる「平均」です。算術平均や相加平均とも呼ばれます。データの合計÷データの数で求めます。
エクセルでは、AVERAGE(データの範囲)で算出されます。
中央値(第2四分位)
データの個数を最大値から数えてちょうど半分のところが中央値です。データの個数が奇数個ならばちょうど半分のところであり、偶数個ならば前後の数を足して2で割った値です。中央値は外れ値の影響を受けにくいのが特徴です。
エクセルでは、MEDIAN(データの範囲)で算出されます。
第3四分位
一番小さな値から75%目の値です。 エクセルでは、QUARTILE(データの範囲, 3)で算出されます。
最大値(第4四分位)
データの中の一番大きな値です。
エクセルでは、MAX(データの範囲)で算出されます。
合計
データの値を足した合計です。
エクセルでは、SUM(データの範囲)で算出されます。
標本数
データの個数です。
エクセルでは、COUNT(データの範囲)で算出されます。
ヒストグラム
棒グラフにより視覚的にデータのばらつきを確認します。
度数
基本統計量を求める対象に文字列が含まれている場合、出現頻度を算出します。
Trunk tools は誰でも簡単に分析できます
クリックだけで分析結果を取得
各分析の集計結果(多次元分析を除く)から行方向、列方向に確認することができます。
気になったらすぐに分析
基本統計量を確認したら
その他の分析も参考に
分析手法一覧から調べたい手法を選択してください。
Trunk toolsでは、業務データから基本統計量をスムーズに行います
すべてのサービスのデータを組み合わせて利用できます
サービス一覧から利用できる業務データをご確認ください。