自社の店舗の実績から出店候補地の売上高を予想
分析の花形 回帰分析
回帰分析といえば、難しそうな計算をするスグレモノ、といったイメージを持つ方もいらっしゃると思います。
確かに計算は難しいです。エクセルでやってもなかなか面倒くさいです。
そして、スグレモノです。
回帰分析で想像されているイメージは、そのまま正しいと思います。
依存関係にある変数間の関係を調べるのが、回帰分析です。
この関係は方程式で表すことができます。
Y = aX + b という方程式を作るのですが、ここでaとbの値を求めるのが回帰分析の肝です。
方程式さえ作ってしまえば、Xにある値を入れてYの値を求めることは簡単です。
Xに色々な値を入れて、Yがどんな値になるか。これが予測するということになります。
ざっくり過ぎてすみません。
細かい理屈は素晴らしいサイトや書籍があるので、そちらをご覧ください。
ただ、道具として回帰分析を使うのであれば、正しい方程式が作れたかどうかさえ分かれば問題ありません。
正しい方程式というのは、Xを入れてYを算出したとき、見当違いの値にならない式、ということです。
計算はコンピュータがやってくれるので、必ず答えを出してくれます。
しかし、本当にそれが正しいのか、現実的なのかは人間が判断してあげる必要があります。
正しい方程式の見分け方
コンピュータは、判断できないまでも、ヒントをくれます。
ヒントを頼りに人間は判断をくだすことになるので、特に計算は必要ありません。
判断としては、完璧な方程式を作ることは不可能なので、このぐらいならあてにしてもいいだろう、といった感じです。
これを「当てはまりがいい」みたいな言い方をします。
ここでは、よく例にあがる「店舗の売上」と「駅からの距離」で分析してみます。
店舗の売上は駅から近いほど多く、逆に遠くなれば少なくなるという考えがもとになっています。
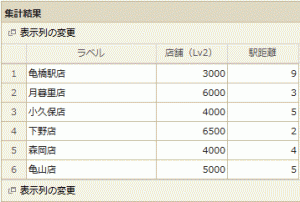
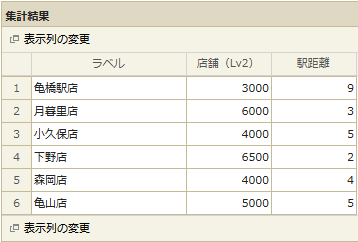
現在6店舗を運営していて、それぞれの店舗の売上を【店舗(Lv2)】の列に、駅からの距離を【駅距離】の列で表しています。
これをもとに以下のような分析結果が求められます。
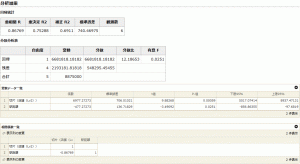
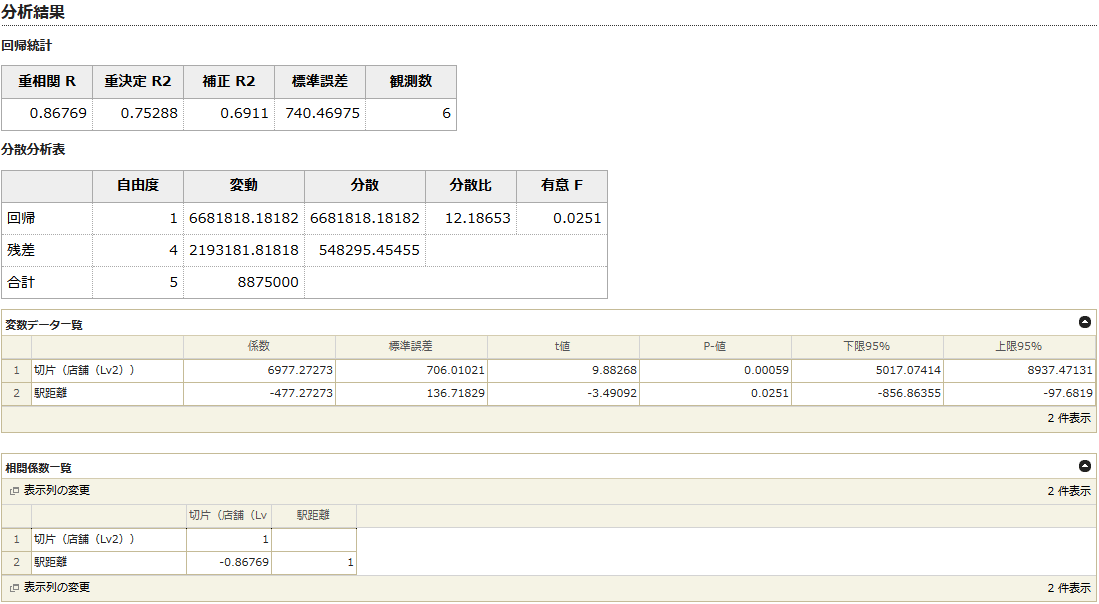
出力される数字は多いのですが、見るべきところは限られています。
ここで算出された方程式は、変数データ一覧の係数の値を見ます。
係数の駅距離がa、切片がbに該当します。
Y = -477.27273X + 6977.27279
これが、方程式です。
Xに駅からの距離を入れると、売上の予測が算出されます。
新しく出店する店舗の駅までの距離が6(キロ)だったら、Xに6を代入して
Y = -477.27273*6 + 6977.27279
Y = 4113.63636(千万円)
と店舗の売上を予測することができます。
これは、勘で算出したのではなく、実際の店舗の情報をもとにして算出したものです。
面白いことに、6(キロ)地点に既存店舗がないにも関わらず、売上を予測することができました。
もしあなたが、5000(千万円)以上の売上を見込みたい場合、残念ながら駅から6(キロ)離れている候補地では基準に達していません。
Xにいくつか値を代入すると、4(キロ)地点で売上金額の予測が、5068.18182(千万円)となりました。
駅から4キロ以下の候補地を対象として検討していくことになります。
では、前後逆になってしまいましたが、算出された方程式が正しいのか、ポイントを4つに絞ってご説明します。
■回帰統計

「補正R2」を確認してください。1に近いほど正しい方程式に近くなります。
以下の4段階に区切って見ていきましょう。
・0.3未満:悪い
・0.3以上0.5未満:やや良い
・0.5以上0.8未満:良い
・0.8以上:非常に良い
結果は0.6911なので、当てはまりは良いです。
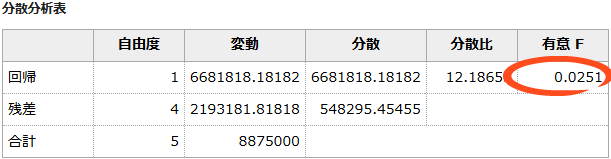
■分散分析表
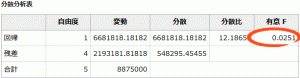
分散分析表の「有意F」を確認します。
この値が0.05より小さな値になっているかで判断します。
結果は0.0251なので、0.05より小さな値になっています。
■変数データ一覧

t値とP-値を見て、駅からの距離が店舗の売上に影響を与えているかを判断します。
変数選択の基準となり、基準を満たせば正しい方程式に近いことになります。
【駅距離】のt値の絶対値が2以下であれば、影響力が少ないので除外します。売上に影響を与えている他の変数に変更したほうがよいということになります。
ここでは、-3.49092なので問題はありません。
また、【駅距離】のP-値が0.05以上であれば、こちらも影響が少ないので除外します。他の変数を検討する必要があります。
0.0251なので問題はありません。
■相関係数一覧
今回の例では、店舗の売上を説明するのに、駅からの距離という一つの変数で回帰分析を行っているので、あまり関係ありません。
もう少し詳しく、「駅からの距離」にプラスして、「駅の乗降者数」もあわせた売上の関係を調べたいときに関係があります。
ちなみに、「店舗の売上」を「駅からの距離」との関係だけで求める、つまり「店舗の売上」を「駅からの距離」だけで説明する場合、単回帰分析と呼びます。
説明している変数が「駅からの距離」1つだけだから“単”です。また、「駅からの距離」という変数を“説明変数”といい、「店舗の売上」を“目的変数”といいます。
先ほどの例のように、「駅の乗降者数」もプラスして正しい方程式を見つける場合、重回帰分析と呼びます。
説明している変数が2つになったから“重”です。説明変数が2つ以上であればすべて重回帰分析と呼ばれます。
相関係数一覧で判断したいのは、多重共線性といわれるものです。
たとえば、「駅からの距離」と「駅からの徒歩時間」はほぼ同じことを説明しています。
こうなると影響を2重に評価してしまい、正しい結果がえらません。
誰でもできる回帰分析
ちょっとしたデータで回帰分析ができました。
すべての条件にあった方程式を見つけることは難しいかもしれませんが、ゲーム感覚でやってみると面白いと思います。
その中で、気づきやアイデアが生まれてくることがあります。
もし、最良の方程式を見つけたら、それはあなたの会社の強力な武器になることでしょう。
Trunk tools ではいくつか分析手法をご用意しています。
是非、目的にあった分析を見つけてください。